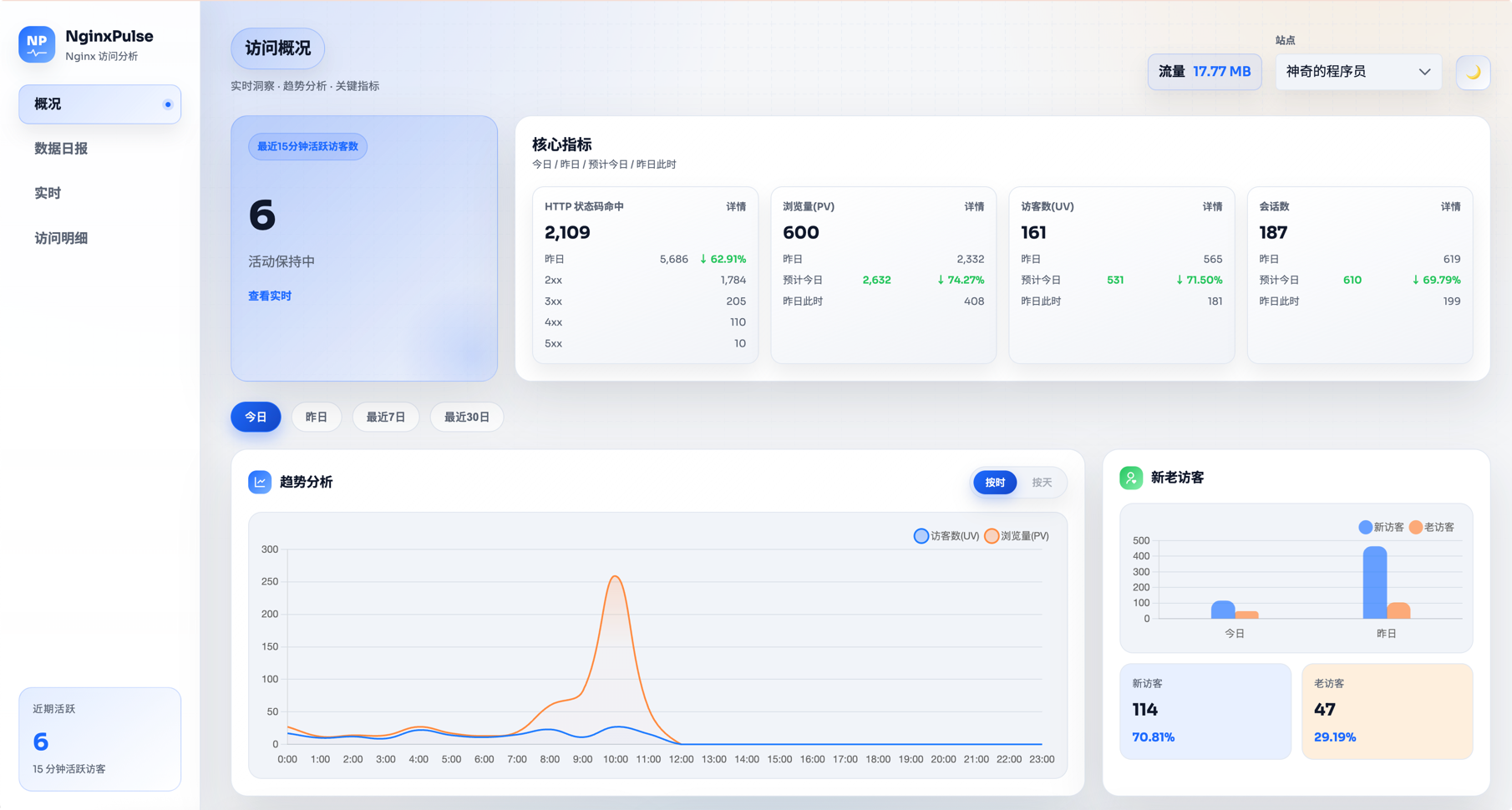
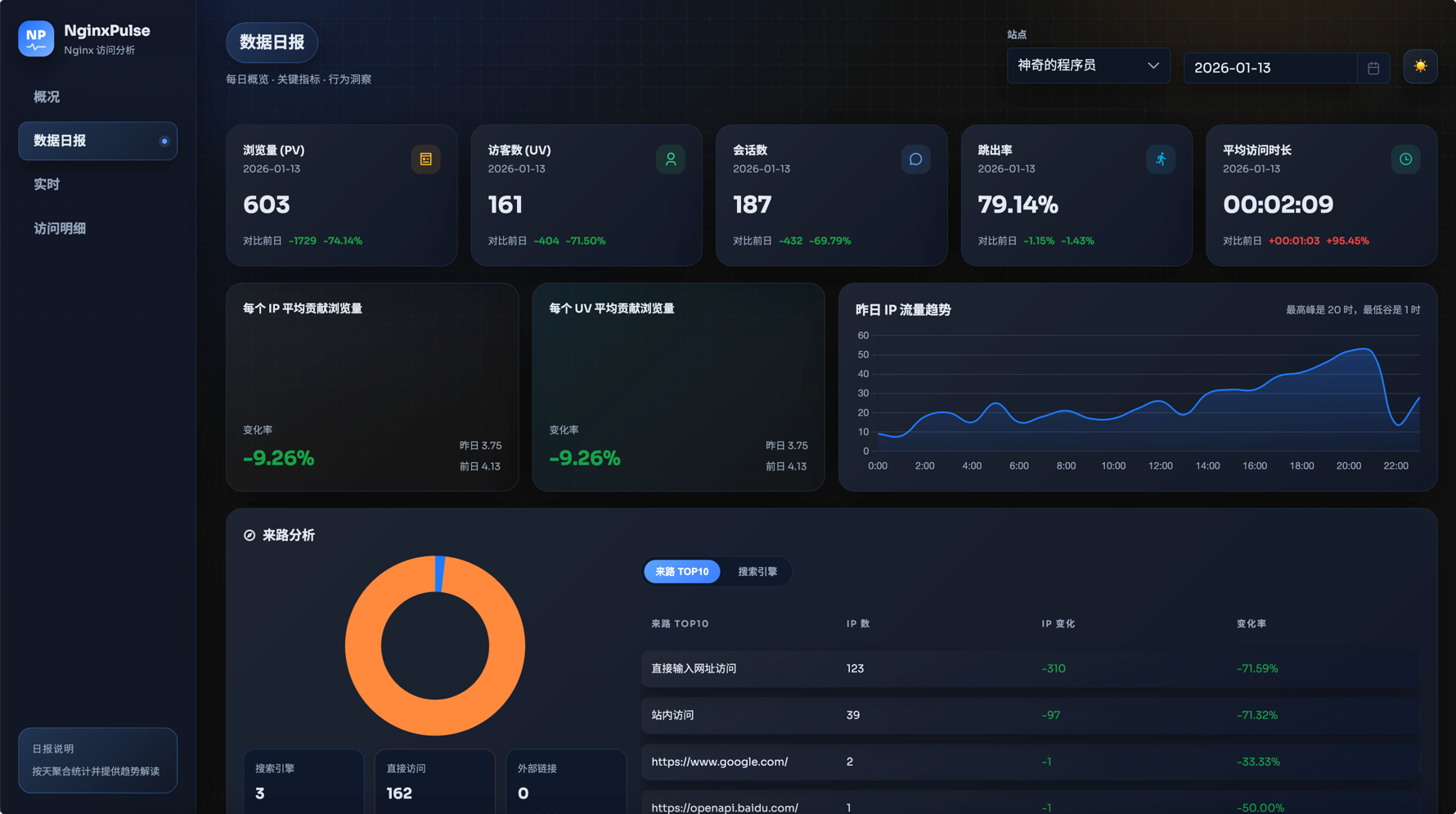
轻量级 Nginx 访问日志分析与可视化面板,提供实时统计、PV 过滤、IP 归属地与客户端解析。
源码仓库:https://github.com/likaia/nginxpulse
文档站点(推荐)
⚠️注意:此文档只讲解了如何使用这个项目,详细文档与示例配置请移步在线文档站点
目录
项目开发技术栈
重要提示(版本 > 1.5.3):已完全弃用 SQLite;单体部署必须自备 PostgreSQL 并配置 DB_DSN(或 database.dsn)。
- 后端:
Go 1.24.x·Gin·Logrus - 数据:
PostgreSQL (pgx) - IP 归属地:
ip2region(本地库) +ip-api.com(远程批量) - 前端:
Vue 3·Vite·TypeScript·PrimeVue·ECharts/Chart.js·Scss - 容器:
Docker / Docker Compose·Nginx(前端静态部署)
IP 归属地查询策略
- 快速过滤:空值/本地/回环地址返回“本地”,内网地址返回“内网/本地网络”。
- 解析解耦:日志解析阶段仅入库并标记“待解析”,IP 归属地由后台任务异步补齐并回填。
- 缓存优先:持久化缓存 + 内存缓存命中直接返回(默认上限 1,000,000 条)。
- 本地优先(IPv4/IPv6):优先查 ip2region,本地结果可用时直接使用。
- 远程补齐:本地返回“未知”或解析失败时,调用远端 API(默认
ip-api.com/batch,可配置)批量查询(超时 1.2s,单批最多 100 个)。 - 远程失败:返回“未知”。
归属地解析未完成时,页面会显示“待解析”,地域统计可能不完整。
本地数据库
ip2region_v4.xdb与ip2region_v6.xdb内嵌在二进制中,首次启动会自动解压到./var/nginxpulse_data/,并尝试加载向量索引提升查询性能。
本项目会访问外网 IP 归属地 API(默认
ip-api.com),部署环境需放行该域名的出站访问。同时也支持自己搭建IP归属地查询服务,详见下文。
如何使用项目
1) Docker
单镜像(前端 Nginx + 后端服务):
镜像内置 PostgreSQL,启动时会自动初始化数据库(未自备数据库时)。必须挂载数据目录:
/app/var/nginxpulse_data与/app/var/pgdata。未挂载时容器会直接退出并报错。 如果你准备在初始化向导里配置外部数据库,可先不挂载pgdata,容器能正常启动;配置完成后重启容器即可生效。
一键启动(极简配置,首次启动进入初始化向导):
docker run -d --name nginxpulse \ -p 8088:8088 \ -v ./docker_local/logs:/share/logs:ro \ -v ./docker_local/nginxpulse_data:/app/var/nginxpulse_data \ -v ./docker_local/pgdata:/app/var/pgdata \ -v ./docker_local/configs:/app/configs \ -v /etc/localtime:/etc/localtime:ro \ magiccoders/nginxpulse:latest
注意:docker_local请替换为你宿主机存在的目录,确保文件权限设置正确,能被容器正常访问,否则会出现无日志的情况。
如果更偏好配置文件方式,可将
configs/nginxpulse_config.json挂载到容器内的/app/configs/nginxpulse_config.json。 若未提供配置文件/环境变量,首次启动会进入“初始化配置向导”。保存后会写入configs/nginxpulse_config.json,需重启容器生效(建议挂载/app/configs以持久化)。
2) Docker Compose
使用远程镜像(Docker Hub):
services:
nginxpulse:
image: magiccoders/nginxpulse:latest
container_name: local_nginxpulse
ports:
- "8088:8088"
- "8089:8089"
volumes:
- ./docker_local/logs:/share/logs
- ./docker_local/nginxpulse_data:/app/var/nginxpulse_data
- ./docker_local/pgdata:/app/var/pgdata
- ./docker_local/configs:/app/configs
- /etc/localtime:/etc/localtime
stop_grace_period: 90s
restart: unless-stopped
docker compose up -d
建议保留
stop_grace_period(如90s),让内置 PostgreSQL 在docker compose stop时有足够时间完成一致性关闭,避免下次启动进入恢复重试。
时区设置(重要)
本项目使用系统时区进行日志时间解析与统计,请确保运行环境时区正确。
Docker / Docker Compose
- 推荐挂载宿主机时区:
-v /etc/localtime:/etc/localtime:ro(Linux) - 若宿主机提供
/etc/timezone,可额外挂载:-v /etc/timezone:/etc/timezone:ro - 若你只想指定时区,可设置
TZ=Asia/Shanghai,但需保证容器内有时区数据(例如安装tzdata或挂载/usr/share/zoneinfo)
单体部署(单进程)
- 默认使用当前系统时区
- 可通过环境变量临时指定:
TZ=Asia/Shanghai ./nginxpulse
移动端访问(/m)
- 入口地址:
http://<host>:8088/m - 移动端仅提供 概览 / 日报 / 实时 / 日志 四个页面
- 首次初始化必须在电脑端完成,移动端会提示在电脑打开
3) 手动构建(前端、后端)
前端构建:
cd webapp pnpm install pnpm run build
移动端构建(/m):
cd webapp_mobile pnpm install pnpm run build
后端构建:
go mod download go build -o bin/nginxpulse ./cmd/nginxpulse/main.go
本地开发(前后端一起跑):
./scripts/dev_local.sh
前端开发服务默认端口 8088,并会将
/api代理到http://127.0.0.1:8089。 本地开发前请准备好日志文件,放在var/log/下(或确保configs/nginxpulse_config.json的logPath指向对应文件)。
4) 单体部署(单进程)
重要提示(版本 > 1.5.3):已彻底弃用 SQLite。单体部署必须自备 PostgreSQL 并配置 DB_DSN(或在 configs/nginxpulse_config.json 填好 database.dsn)。
从仓库的releases下载对应平台的二进制文件,执行即可。
执行后会生成单体可执行文件(已内置前端静态资源),启动后即可同时提供前后端服务:
- 前端:
http://localhost:8088 - 后端:
http://localhost:8088/api/...
单体部署的配置方式
单体运行时读取配置有两种方式(任选其一):
方式 A:配置文件(默认)
- 在运行目录创建
configs/ - 放入
configs/nginxpulse_config.json - 启动:
./nginxpulse
方式 B:环境变量注入(无需文件)
CONFIG_JSON="$(cat /path/to/nginxpulse_config.json)" ./nginxpulse
注意事项:
- 配置文件路径为相对路径
./configs/nginxpulse_config.json,请确保运行时工作目录正确。 - 如果使用 systemd,请设置
WorkingDirectory,或改用CONFIG_JSON注入。 - 数据目录
./var/nginxpulse_data也是相对路径;找不到目录时请先确认当前进程的工作目录。
5) Makefile 构建
此项目也支持了通过Makefile来构建相关资源,命令如下:
make frontend # 构建前端(含移动端)webapp/dist + webapp_mobile/dist make frontend-mobile # 仅构建移动端 webapp_mobile/dist make backend # 构建后端 bin/nginxpulse(不内嵌前端) make single # 构建单体包(内嵌前端 + 复制配置与gzip示例) make dev # 启动本地开发(前端8088,后端8089) make clean # 清理构建产物
指定版本号示例:
VERSION=v0.4.8 make single VERSION=v0.4.8 make backend
说明:
make single默认构建linux/amd64与linux/arm64,产物在bin/linux_amd64/与bin/linux_arm64/。- 单平台构建时,产物在
bin/nginxpulse,配置在bin/configs/nginxpulse_config.json(端口默认:8088),gzip 示例在bin/var/log/gz-log-read-test/。
Docker 部署权限说明
镜像默认以非 root 用户(nginxpulse)运行。容器里能否读取日志、写入数据,取决于宿主机目录的权限。你在容器里用 cat 看到日志,通常是因为 docker exec 默认是 root,不代表应用用户有权限。
推荐做法:让容器内用户的 UID/GID 与宿主机日志/数据目录的属主一致。
步骤 1:查看宿主机目录的 UID/GID
ls -n /path/to/logs /path/to/nginxpulse_data /path/to/pgdata # 或 stat -c '%u %g %n' /path/to/logs /path/to/nginxpulse_data /path/to/pgdata
步骤 2:启动容器时传入 PUID/PGID(与上面一致)
docker run ... \ -e PUID=1000 \ -e PGID=1000 \ -v /path/to/logs:/var/log/nginx:ro \ -v /path/to/nginxpulse_data:/app/var/nginxpulse_data:rw \ -v /path/to/pgdata:/app/var/pgdata:rw \ ...
步骤 3:确保目录对该 UID/GID 可读/可写
chown -R 1000:1000 /path/to/nginxpulse_data /path/to/pgdata chmod -R u+rx /path/to/logs
如果你使用外部数据库(设置 DB_DSN),可以不挂载 pgdata。外置 PG 推荐使用 16 版本。 若你通过初始化向导配置外部数据库,同样可以不挂载 pgdata,保存后重启容器生效。
SELinux 说明(RHEL/CentOS/Fedora 等):
- 这些系统默认启用 SELinux,Docker 挂载目录可能因安全上下文导致“看得见但不可访问”。
- 解决办法是在 volume 后加
:z或:Z重新打标签::Z让该目录仅供当前容器使用(更严格)。:z让该目录可被多个容器共享使用。
docker run ... \ -v /path/to/logs:/var/log/nginx:ro,Z \ -v /path/to/nginxpulse_data:/app/var/nginxpulse_data:rw,Z \ -v /path/to/pgdata:/app/var/pgdata:rw,Z \ ...
不推荐做法:直接 chmod -R 777。这虽然省事,但权限过宽不安全,仅建议临时排查时使用。
常见问题
- 日志明细无内容
通常是容器内无权限访问宿主机日志文件。请先阅读《Docker 部署权限说明》并按步骤处理权限。 - 日志存在,但 PV/UV 无法统计
默认规则会排除内网 IP。若你希望统计内网流量,请将PV_EXCLUDE_IPS设为空数组并重启:
PV_EXCLUDE_IPS='[]'
重启后在“日志明细”页面点击“重新解析”按钮。
- 日志时间不正确
通常是运行环境时区未同步导致。请确认 Docker/系统时区正确,并按“时区设置(重要)”章节调整后重新解析日志。 - 无法启动 报错 tmp 目录无权限写入问题(旧版本可能出现),如果容器启动后出现如下所示的报错,请确认
nginxpulse_data可写(具体权限问题请阅读《Docker 部署权限说明》),或设置TMPDIR到可写目录。
nginxpulse: initializing postgres data dir at /app/var/pgdata /app/entrypoint.sh: line 91: can't create /tmp/tmp.KOdAPn: Permission denied
解决办法(任选其一):
-e TMPDIR=/app/var/nginxpulse_data/tmp
- 解析入库的数据会一直保留吗
不会。入库后的访问数据会按system.logRetentionDays定时清理(默认 30 天)。
例如你一次解析了几个月数据,后续仍会逐步清理掉保留天数之外的数据。
注意:该参数不影响原始 Nginx 日志文件,也不等于系统运行日志(var/nginxpulse_data/nginxpulse.log)的轮转策略。
目录结构与主要文件
.
├── cmd/
│ └── nginxpulse/
│ └── main.go # 程序入口
├── internal/ # 核心逻辑(解析、统计、存储、API)
│ ├── app/
│ │ └── app.go # 初始化、依赖装配、任务调度
│ ├── analytics/ # 统计口径与聚合
│ ├── enrich/
│ │ ├── ip_geo.go # IP 归属地(远程+本地)与缓存
│ │ └── pv_filter.go # PV 过滤规则
│ ├── ingest/
│ │ └── log_parser.go # 日志扫描、解析与入库
│ ├── server/
│ │ └── http.go # HTTP 服务与中间件
│ ├── store/
│ │ └── repository.go # PostgreSQL 结构与写入
│ ├── version/
│ │ └── info.go # 版本信息注入
│ ├── webui/
│ │ └── dist/ # 单体嵌入的前端静态资源
│ └── web/
│ └── handler.go # API 路由
├── webapp/
│ └── src/
│ └── main.ts # 前端入口
├── webapp_mobile/ # 移动端前端(/m)
│ └── src/
│ └── main.ts # 移动端入口
├── configs/
│ ├── nginxpulse_config.json # 核心配置入口
│ ├── nginxpulse_config.dev.json # 本地开发配置
│ └── nginx_frontend.conf # 内置 Nginx 配置
├── docs/
│ └── versioning.md # 版本管理与发布说明
├── scripts/
│ ├── build_single.sh # 单体构建脚本
│ ├── dev_local.sh # 本地一键启动
│ └── publish_docker.sh # 推送 Docker 镜像
├── var/ # 数据目录(运行时生成/挂载)
│ └── log/
│ └── gz-log-read-test/ # gzip 参考日志
├── Dockerfile
└── docker-compose.yml
如需更详细的统计口径或 API 扩展,建议从 internal/analytics/ 与 internal/web/handler.go 开始。