每个月,Netflix在190+个国家播放数十亿小时的视频。Spotify 运行着数千个微服务,为 6 亿+ 百万用户提供支持。谷歌每天处理超过85亿次搜索。这些系统怎么可能不因自身重量而崩溃?
答案不是更多服务器。它不是一个神奇的数据库,也不是一种更快的编程语言。这是一种编排系统;一个唯一任务是管理跨成千上万台机器运行的其他软件的软件。
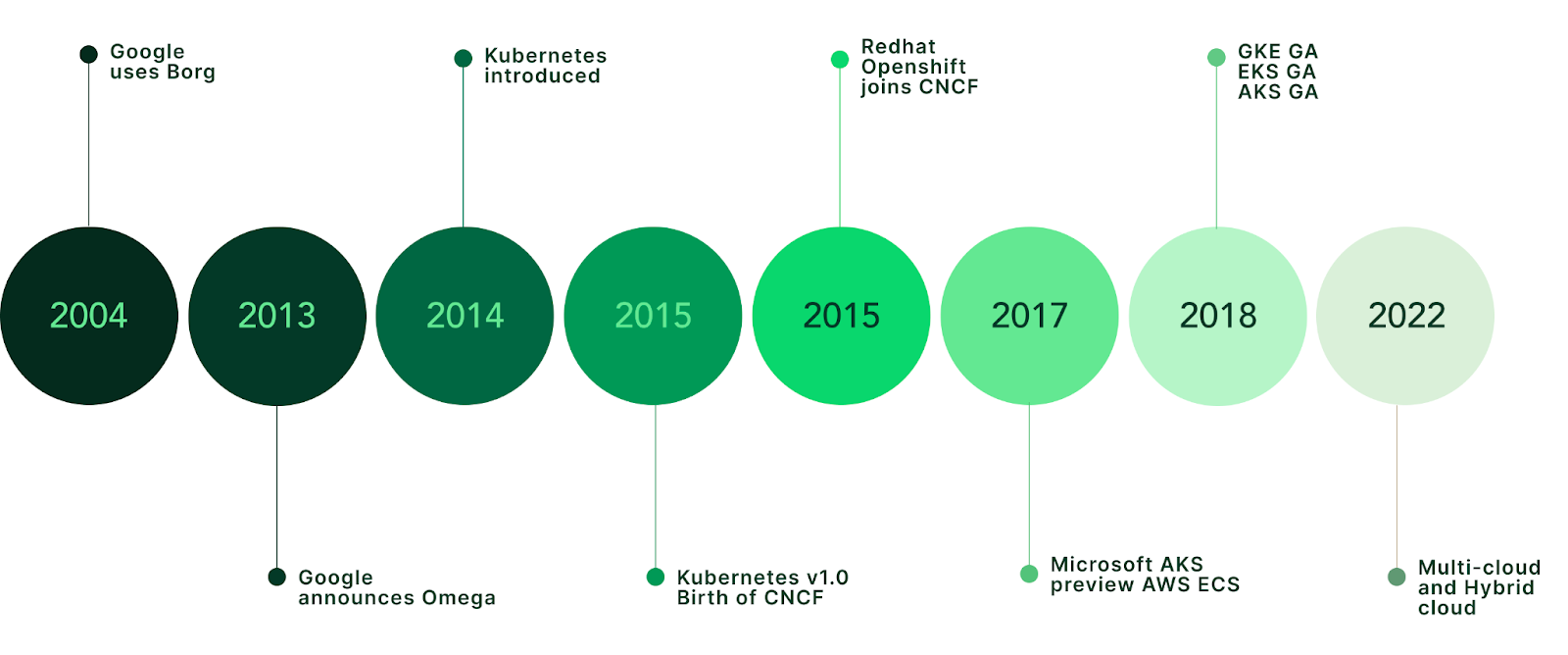
最受欢迎的是叫 Kubernetes,最初是谷歌内部的一个项目 Borg。
从 Borg 到 Kubernetes
2003年,谷歌遇到了一个问题。他们在一系列商品服务器上运行搜索、广告、Gmail,最终还有YouTube。在他们的规模下,手动部署和管理是不可能的。于是他们开发了Borg,一个内部集群管理系统,帮助他们协调一切。
博格本就不该公开。它在谷歌内部默默运行了十多年,后来他们透露每周发布的集装箱数量高达20亿个。1
2013年,Docker 使容器对所有人开放。突然间,将应用打包到独立、便携的设备中,不再只是谷歌的专利。但 Docker 只解决了“我如何打包这个应用”的问题,而不是“如何在 500 台机器上运行 10,000 个实例”的问题。
谷歌看到了这个差距。2014年,他们宣布了Kubernetes(希腊语意为“舵手”或“飞行员”)2,一个基于运行Borg经验教训构建的开源容器编排系统。他们于2015年将其捐赠给新成立的云原生计算基金会,使其实现了云供应商中立。
几年内,Kubernetes 成为事实上的标准。AWS、Azure和Google Cloud都提供托管Kubernetes服务。生态系统爆发式发展:Helm用于包管理,Prometheus用于监控,Istio用于服务网格。
谷歌为运行自身基础设施而构建的系统现在对所有人开放。
为什么选择配器?
在 Kubernetes 之前,大规模部署软件大致如下:
- SSH连接到服务器1
- 拉取最新的代码
- 安装依赖
- 开始申请
- 服务器2到N重复此过程
- 希望凌晨3点没崩溃
这是基础设施管理的关键。你一步步告诉每台机器该做什么。它不具备扩展性,容易出错,当东西坏了,你才是被呼叫的人。https://blog-animations.vercel.app/kubernetes/images/declarative-vs-imperative声明式与命令式的比较
Kubernetes颠覆了这一模式。你没有指定如何部署,而是指定你想要的最终状态:3
YAML音乐
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3就这样。“我要3份我的应用在运行。”Kubernetes会帮你解决剩下的;使用哪些机器,如何分配负载,甚至当机器崩溃时该怎么办。
这就是声明式基础设施。你宣告你想要的状态,系统会不断努力让现实与你的宣言相匹配。https://blog-animations.vercel.app/kubernetes/control-loopKubernetes 控制循环——观察期望状态和实际状态如何对账
魔法发生在所谓的控制循环中。控制器会持续监控集群的实际状态,将其与你期望的状态(你的YAML)进行比较,并采取措施修复任何潜在的漂移。如果服务器故障并带走了你的两个Pod,控制器会发现并在健康机器上启动替换。没人需要被呼叫。
构建模块
让我们先从基础开始。
集装箱
在Kubernetes之前,有Docker。Docker 容器是一种轻量级、自包含的软件单元,包含运行所需的一切:代码、运行时、库和依赖。
可以把它想象成一个字面意义上的集装箱。在标准化集装箱出现之前,装载货物非常混乱;不同尺寸、不同的操作需求、不同的设备。标准化集装箱改变了全球贸易,因为任何船只、火车或卡车都可以处理任何集装箱。
软件容器也是同样的。但有一个重要的区别:图像是包(蓝图),容器是该图像的运行实例。你只需用应用及其所有依赖构建一个镜像,推送到注册表,然后从该镜像在任何地方运行容器;你的笔记本电脑、测试服务器、生产环境,任何云端都可以。
砰
# Build a Docker image (the blueprint)
docker build -t my-app:v1 .
# Run a container from that image
docker run -p 8080:8080 my-app:v1
# Push the image to a registry
docker push myregistry/my-app:v1舱体
舱体是Kubernetes中最小的可部署单位。它是包裹一个或多个共享存储和网络资源的容器的包裹器。4https://blog-animations.vercel.app/kubernetes/images/pod-anatomy舱体解剖图
大多数舱内只有一个容器。但有时候你需要侧车容器;一个日志代理、一个代理、一个数据同步器。同一Pod中的容器可以在上相互访问并共享挂载的卷(文件系统)。localhost
把舱体想象成公寓。容器是室友,他们共用厨房和客厅,但各自有自己的卧室。
YAML音乐
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: app
image: nginx:1.14.2
ports:
- containerPort: 80
# Second container
- name: sidecar
image: fluent/fluent-bit节点
节点是一种运行 pod 的机器(物理或虚拟)。每个节点都有一个代理与控制平面通信,确保容器按预期运行。kubelet
工作节点负责实际工作;运行你的应用容器,而控制平面节点运行 Kubernetes 本身。
星团
集群是一组节点(包括工作面和控制面)协同工作的节点。至少,你有:
- 控制平面:大脑。存储状态,做排班决策,管理控制器。
- 工节点:肌肉。实际上它能运行你的工作负载。
https://blog-animations.vercel.app/kubernetes/images/cluster-architecture集群架构图
当你运行 kubectl 命令时,你是在与控制平面的 API 服务器通信,服务器随后与工作节点协调以实现任务。
服务(稳定网络)
舱体是短暂的,或短暂的。他们来来去去。每次创建时都会获得新的IP地址。那么系统的其他部分是如何可靠地与它们通信的呢?
服务提供稳定的网络端点。5服务位于一组Pod前方,提供一个统一的IP地址和DNS名称。所有流量都会在所有健康舱之间自动负载均衡。
YAML音乐
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- port: 80
targetPort: 8080
# Common Internal-only Service
type: ClusterIP现在,其他服务不再追踪单个Pod的IP,而是直接调用。my-service:80
部署
部署实际上是帮你管理舱体。你声明要多少副本(相同的运行舱),运行哪个镜像,剩下的由部署控制器处理。
部署还会处理滚动更新。当你推送新版本时,Kubernetes会逐步用新Pod替换旧Pod,确保零停机。如果新版本坏了,你只需一个命令就能回滚。https://blog-animations.vercel.app/kubernetes/yaml将鼠标悬停在YAML上,可以看到每个字段生成的内容
动手体验:你的第一个集群
我们真的来运行 Kubernetes。Minikube 会在你的本地机器上创建一个单节点集群。
砰
# Install minikube (macOS)
# Installation guide: https://minikube.sigs.k8s.io/docs/start/
brew install minikube
# Start a cluster
minikube start
# Verify it's running
kubectl get nodes你应该会看到这样的输出:
文本
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane 30s v1.34.0现在让我们部署一些东西:
砰
# Create a deployment
kubectl create deployment hello --image=nginx
# Check the pod
kubectl get pods文本
NAME READY STATUS RESTARTS AGE
hello-5d7b9d8c7f-x2k4j 1/1 Running 0 10s放大它:
砰
# Scale to 3 replicas
kubectl scale deployment hello --replicas=3
# Watch pods come up
kubectl get pods -w文本
NAME READY STATUS RESTARTS AGE
hello-5d7b9d8c7f-x2k4j 1/1 Running 0 30s
hello-5d7b9d8c7f-m8n2p 1/1 Running 0 5s
hello-5d7b9d8c7f-q9r3s 1/1 Running 0 5s将其作为服务曝光:
砰
# Create a LoadBalancer service
kubectl expose deployment hello --type=LoadBalancer --port=80
# Get the URL (minikube specific)
minikube service hello --url你现在拥有了一个负载均衡、可扩展的 Kubernetes 网络服务器。在你的笔记本电脑上。
完成后如何清理:
砰
# Delete the service and deployment
kubectl delete service hello
kubectl delete deployment hello
# Stop the minikube cluster (frees up memory)
minikube stop
# Or delete the cluster entirely
minikube deletehttps://blog-animations.vercel.app/kubernetes/cluster互动集群——尝试部署、扩展和杀死小队
深度潜入
扩展基础设施才是Kubernetes真正闪耀的地方。有三个维度:
1. 水平舱自动标配(HPA)
负载增加时,更多舱体。这是最常见的方法。
YAML音乐
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50翻译:
“保持2到10个舱体。如果平均CPU超过50%,就加装Pods。如果掉到下面,就移除舱体。”
https://blog-animations.vercel.app/kubernetes/images/hpa-scalingHPA缩放可视化
HPA控制器默认每15秒检查一次指标。它比较保守,不会立刻缩小以防止暴打。
2. 垂直舱自动缩放(VPA)
用更大的舱体而不是更多的舱体。VPA会调整现有Pod的CPU和内存请求/限制。
这适用于:
- 无法并行化的单线程应用程序
- 舱启动成本较高的工作负载
- 数据库与有状态应用
YAML音乐
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
updatePolicy:
updateMode: Auto3. 集群自动缩放
当无法调度舱时,节点会更多。集群自动扩展器会监控卡在状态中的Pod(通常是因为现有节点CPU或内存不足),并自动从你的云服务商配置新节点。Pending
当负载降低且节点利用不足时,它通过排空和移除节点来缩减规模。它不会移除具有以下条件的节点:
- 非复制的舱体(如DaemonSets))
- 带有任何本地存储的Pod
- 带PodDisruption的Pod防止被淘汰的预算
以下是配置方式(AWS EKS 示例):
YAML音乐
apiVersion: autoscaling.k8s.io/v1
kind: ClusterAutoscaler
metadata:
name: cluster-autoscaler
spec:
scaleDown:
enabled: true
delayAfterAdd: 10m
unneededTime: 10m
resourceLimits:
minNodes: 2
maxNodes: 10
cores:
min: 4
max: 100
memory:
min: 8
max: 256内容如下:
“保持2到10个节点之间。缩放后,等待10分钟再考虑缩减。移除那些已经10+分钟未充分利用的节点。”
实际操作中的情况:
- HPA可以从3→10个部署舱扩展到你
- 有些小组无法安排时间(资源不足)→
Pending - 集群自动缩放器看到后,会新增两个节点
- 待处理的 Pod 会被调度到新的节点
- 后来流量下降,HPA会缩减舱群规模
- 在利用率不足10分钟后,集群自动调整器会移除多余的节点
这就是扩展故事的全部:
- HPA:节点内的扩展舱体
- VPA:按字面尺寸缩放舱体尺寸
- 集群自动缩放器:调整节点本身
控制平面:引擎盖之下
是时候看看到底是什么在运行 Kubernetes。https://blog-animations.vercel.app/kubernetes/images/control-plane控制平面组件图
API服务器
前门。每一个命令、每一个控制器操作、每一个节点的心跳都经过API服务器。它是唯一直接与 etcd 通信的组件。kubectl
它暴露了REST API,并处理认证、授权和准入控制。
etcd
真相的源头。6etcd 是一个分布式键值存储器,存储所有集群状态:哪些 pod 存在,哪些节点健康,哪些秘密存储,哪些配置地图定义。
Kubernetes 里的所有东西都存储在 etcd 里。没有备份就丢失etcd,也失去集群状态。
调度器
当你创建一个 pod 时,调度器会决定哪个节点运行它。它考虑了:
- 资源需求(CPU,内存)
- 节点亲和力/反亲和规则
- 污染与耐受
- 当前节点利用情况
调度器实际上不会启动舱体。它只是通过写入 etcd 来分配节点。该节点上的 kubelet 会接收并完成实际工作。
财务主管
这里是控制环路所在的地方。每个控制器监控特定资源类型,并努力将实际状态与期望状态进行协调:
- 部署控制器:确保存在正确数量的复制集
- ReplicaSet 控制器:确保存在正确数量的 Pod
- 节点控制器:监控节点健康状况,驱逐故障节点的舱体
- 服务控制器:为负载均衡器服务创建云负载均衡器
库贝莱特
代理人7在每个工作节点上。它:
- 从API服务器接收Pod规格
- 与容器运行时(containerd、CRI-O)配合启动容器
- 向控制平面报告节点和舱体状态
- 运行活性和准备探测器
到底谁会用 Kubernetes?
这听起来很多,甚至可能对很多事情有点过头了。Kubernetes 不仅仅是解决谷歌规模的问题,更有助于看到谁在大规模运行它。
- Spotify:4000+微服务,从他们内部的Helios系统迁移过来。它们在区域内运行多个集群,拥有数千个节点。
- Pinterest:它们集群中共有250,000+个Pods。他们建立了自己的Kubernetes平台团队和工具。
- Airbnb:从单一的Rails应用转向基于Kubernetes的微服务。他们在所有环境中统一使用 Kubernetes。
为什么公司选择Kubernetes?
诉求始于供应商中立性。你可以在任何云端(AWS、GCP、Azure,或你自己的数据中心)上运行完全相同的工作负载。从一个云端开始,如果价格变动或需求变化,可以转到另一个云端。无需重写应用代码,也无需厂商锁定。
然后是生态系统。Helm Charts 用于包管理,Prometheus 用于指标,Istio 用于服务网格,ArgoCD 用于 GitOps 部署。围绕Kubernetes的工具无与伦比,因为大家都基于它进行了标准化。需要解决问题吗?可能已经有一个维护良好的开源工具了。
但真正的作战胜利是自我修复。舱体坠毁了?Kubernetes 会自动重启它。节点死亡?Pod 会在几秒钟内重新调度到健康节点。部署发生内存泄漏?设定资源限制后,敌人会被击杀并重启,才能击败邻居。这时工程师凌晨3点不会被呼叫。
最后,一切都是声明性。你的整个运行环境(部署、服务、秘密、配置)都存在于版本控制的YAML中。想看看网站宕机后发生了什么变化吗?想要回滚吗?撤销提交。它是基础设施即代码,但涵盖整个栈,而不仅仅是虚拟机。git diff
更大的视角
Kubernetes 不仅仅是一个部署工具。这是我们对基础设施思考方式的范式转变。
同样的模式支撑着谷歌搜索,运行着Netflix4亿+百万小时的月流媒体播放,以及Spotify的4000个微服务;也对任何学习写YAML并以声明式思维方式进行的人开放。
从谷歌的博格管理数十亿个容器,到你在笔记本电脑上运行,抽象层面是一样的。基础设施的复杂性隐藏在一个干净的API背后。kubectl
我们从手动SSH服务器到用代码声明基础设施。这不仅仅是自动化;这是我们对软件运行思维方式的根本转变。
学习曲线确实存在。YAML内容繁琐。人脉关系会让你至少怀疑一次自己的职业选择。但一旦你真正明白了,你就能使用全球最大公司使用的相同基础设施模式。
→ 凯尔
注释
- 1.博格论文于2015年在EuroSys发表。它说谷歌每周推出超过20亿个集装箱。
- 2.“Kubernetes”常缩写为“K8s”(发音为“kay-ates”)。这是一种数字词,8代表’K’和’s’之间的八个字母。类似的模式:i18n(国际化)、a11y(无障碍)。
- 3.声明式与命令式:在命令式编程中,你要一步步指定如何实现结果。在声明式编程中,你指定想要的结果,让系统自己决定如何实现。SQL 是声明式的(“给我所有年龄> 21 岁的用户”),而对数组进行 for-loop 过滤是必不可少的。
- 4.Pod 内部结构:Pod 通过 Linux 内核特性实现:命名空间(用于网络隔离、PID、挂载点)和 cgroups(用于资源限制)。同一Pod中的容器共享网络命名空间(它们可以在localhost上相互访问),并且可以共享卷。
- 5.服务类型:Kubernetes 提供多种服务类型:ClusterIP(默认)将服务暴露在仅能在集群内部访问的内部 IP。NodePort 在每个节点的静态端口(30000-32767)上暴露 IP。LoadBalancer 提供外部负载均衡器(云服务提供商专用)。ExternalName 映射到 DNS 名称。服务使用标签选择器来确定哪些Pod接收到流量。
- 6.etcd:一种分布式键值存储,使用Raft共识算法在多个节点间保持一致性。它存储所有集群状态:Pod 规格、秘密、配置文件地图、服务账户。名称来源于 Unix 的“/etc”目录(用于配置)+ “d”(分布式)。
- 7.资源限制与OOMKilled:没有资源限制,单个Pod可以消耗节点上的所有CPU/内存,导致其他Pod陷入饥饿。Kubernetes 使用请求(保证最低请求)和限制(硬上限)。如果容器超过其内存限制,内核的 OOM(内存外)杀手会终止该容器;你会看到“OOMKilled”显示在舱内状态。CPU的限制机制不同:容器被限速,而不是被杀死。
发表回复